A friend shared with me an article on GitHub’s official blog boasting a “scientifically significant” study on GitHub Copilot’s effectiveness. I read it out of curiosity, but it rubbed me the wrong way. So, here’s a rant about it.
To understand my ramblings, you will need context, so here is the original article, titled: Does GitHub Copilot improve code quality? Here’s what the data says. For the purposes of discussion, I link to a few images directly from the post, just in case they become unavailable, here’s a web archive.
Acknowledging the Bias #
I make it no secret that I am against the AI Hype train. So as much as I’d like to stay impartial for this, I must acknowledge my internal bias against the findings of this study.
I’m not a scientist either, and my opinions aren’t facts, but as a software developer I’ve accrued a fantastic bullshit detector towards tech marketing, and this article maxed out its gauges.
On the other hand, you cannot blame me from being skeptical of a big corporation conducting a study on its own products, since they only stand to gain if their conclusions are positive.
If anything, this might just be a biased dude versus a biased corporation, but I hope that if it will not be useful, it will at least be entertaining.
The Headline #
Let’s analyze the headline with a bit of cynicism. It asks a valid question, and promises an answer backed up by data. The subtitle reads as follows:
Findings in our latest study show that the quality of code written with GitHub Copilot is significantly more functional, readable, reliable, maintainable, and concise.
The study shows, as in proves, that Copilot writes significantly better code. If you stop reading here, you might just be convinced. Remember that word, “significantly”, as it will later be… significant! 🥁
Since there are a lot of comparisons between “people who used” and “people who didn’t” I will instead label them as “Copilot-ers” and “Control-ers”, for brevity.
What Was Tested? #
The short and sweet is this:
The participants were all asked to complete a coding task writing API endpoints for a web server.
Right out of the gate, we see a biased experiment, CRUDs… One of the most boring, repetitive, uninspired, and cognitively unchallenged aspects of development (which nonetheless is a worryingly large proportion of your JIRA backlog LOL).
And hey, let’s be fair, that’s what they want to automate with AI, the boring stuff, so we can do the cool stuff. Right? Although it’s not as honest to draw the conclusion that AI improves your code in general, without mentioning these improvements were observed in the place we’d most expect.
An API is a pretty complex thing when you consider all the different components you need to wire together! Yes, it is extremely complicated when you actually do complex stuff; not the case here, later in the methodology section they elaborate:
Each group completed a coding exercise for a web server of fictional restaurant reviews.
If that isn’t the most spammed code-lab medium-article stack-overflow-marked-as-duplicate-of-the-year task ever, I don’t know what is. I bet you even GPT-2.0 could plagiarize that code after scraping Google for two weeks.
If you really want to test this Copilot, give it complex tasks, diverse tasks that involve huge SQL queries, regular expressions, shell-script deployments, anything more impressive than defining some REST stubs and type hints in Python.
The Findings #
Let’s have a look at the claims made. All the numbers given are accompanied by impressive-looking p-values, which I will take for granted for the sake of argument.
The key takeaways, paraphrased are:
- Copilot-ers are 56% more likely to pass all tests;
- Copilot-ers can write 13% more code before introducing code smells;
- Copilot-ers are 3.62% more readable, 2.94% more reliable, 2.47% more maintainable, and 4.16% more concise;
- Copilot-ers are 5% more likely to have their PR accepted.
(Mis-)Leading With Percentages #
The first thing you’ll notice is they lead the article with key takeaways measured in percentage points. Which is misleading, because percentages mean nothing without context. If I get a 3% increase in accuracy from the previous 95%, that is impressive. If I get the same 3% increase from the previous 32%, much less so.
Some might also argue that the code metrics are rounding errors, since they all edge around 3%. GitHub says no, it’s significant! And yes, statistically speaking, they might as well be. But as an end user, would you even scoff at a bag of crisps claiming it now uses 3% less oil?
Lucky for us, they provide context, let’s learn!
Bad Graphs and Bad Numbers #
The biggest percentage was that “56% more likely to pass the tests with flying colors” bit. It is further explained by this visual aid:

(*)Please note that the percentages in these graphs do not add up to 100% because the math was done by an LLM.
Not sure why they lead with the negative bar, but I digress. We can now quantify it in absolute percentages.
Hmm, that’s a pretty favorable indicator if GitHub Copilot is so good at preventing edge cases that it passes all tests first try!
… that passed all 10 unit tests …
All what?! A whopping 10 entire unit tests? Man, that’s thorough. This either means the entire test run was implementing a single endpoint, or that the tests are very shallow. I wonder how specific about edge cases they were. I mean, it’s an API, plenty of stuff to check like content negotiation headers, status codes subtleties (200 vs 201 vs 204) or whatever else.
Oh, btw, I didn’t read you the first half of that sentence:
The 25 developers who authored code that passed all 10 unit tests.
They say that 25 developers aced the trial of the unit tests. Wait… what? OK so bear with me, we have about 40% who aced and 60% who didn’t, and 25 developers aced it so that means… carry the one… there’s 62 developers in total?
But they said there’s 200, split randomly in halves, where did the 40 extra Control-ers go?!
Swapping Definitions #
The next statistically significant (according to p-value) metric they provide is average lines of code authored per code error:

This is exactly the misleading percentage I talked about. It was first presented as 13% more lines of code on average without errors. Wowza!!1 Then you look at the actual numbers, and it’s a measly two more lines.
“But Dan”, I hear you say, “don’t be so critical, I mean after all those errors add up in time! You’ve got to be a little more open-minded and think about the big picture!”
You are right when you say “Well, bugs are best to be avoided”, but I don’t dare be as open-minded as GitHub, from fear of rendering dictionaries useless. If you keep reading, further in the article they hit you with this gem:
In this study, we defined code errors as any code that reduces the ability for the code to be easily understood. This did not include functional errors that would prevent the code from operating as intended, but instead errors that represent poor coding practices.
Wait, what? Here, errors don’t include the actual bugs, or actual syntax errors, they include:
inconsistent naming, unclear identifiers, excessive line length, excessive whitespace, missing documentation, repeated code, excessive branching or loop depth, insufficient separation of functionality, and variable complexity.
That’s not an error, those are linter warnings.
The only way you could consider this valid is if you are one of those purists that -Wall -Werror so every CI build
fails at least once.
Ok, can’t blame you, I do this myself sometimes, but that isn’t what GitHub is doing here.
What they basically said is “it’s not an issue if you have logic errors, so long as your formatting is pristine, we can fix those later, right now, what’s important is getting an A on SonarQube’s quality gate to please the PO.”
Quality Measure and Evaluation Metrics #
Next they show you how, on average (and remember, statistically significant!), Copilot produces three percent-ish better code, as shown here:

Code style and code reviews are a highly subjective area, and entire flame wars have been waged over eslint rules,
indentation styles, curly placements, and other pedantry.
So we must all agree that human intuition is the only metric we can have for the categories being tested.
OK, fair.
Except… we don’t know how they did it.
There’s no mention of whether they used grades, stars, points, or T-shirts.
I, for one, am very curious to know more about how the metrics were measured (according to them, I should email to ask!), because they must be very accurate if their results prove within such small p-values improvements of 1-3%…
Also, humans have biases towards their own convictions (we can prove this by looking at all the people who swear by JavaScript even if it is objectively one of the worst languages. 😏) and would naturally incline to award better scores to code that more closely aligned with their own style. It is therefore extremely difficult to conclude whether, if Copilot does indeed produce more readable code, is it because it’s objectively more readable or is it just a more popular format?
It also seems that the same developers who submitted code were tasked with reviewing 10 other submissions, grading each-other. I would have preferred to have a third, impartial group grade these, but I guess they couldn’t afford a bigger sample.
At the very least, I can appreciate they only made the developers who passed all unit tests do the reviewing. But remember, dear reader, that you’re baited with a 3% increase in preference from some random 25 developers, whose only credentials (at least mentioned by the study) is holding a job for 5 years and passing 10 unit tests.
LGTM, Ship It! 🚀 #
Their final beautifully rendered graph is the one showing how you can get a 5% increase in PR approval without comments:
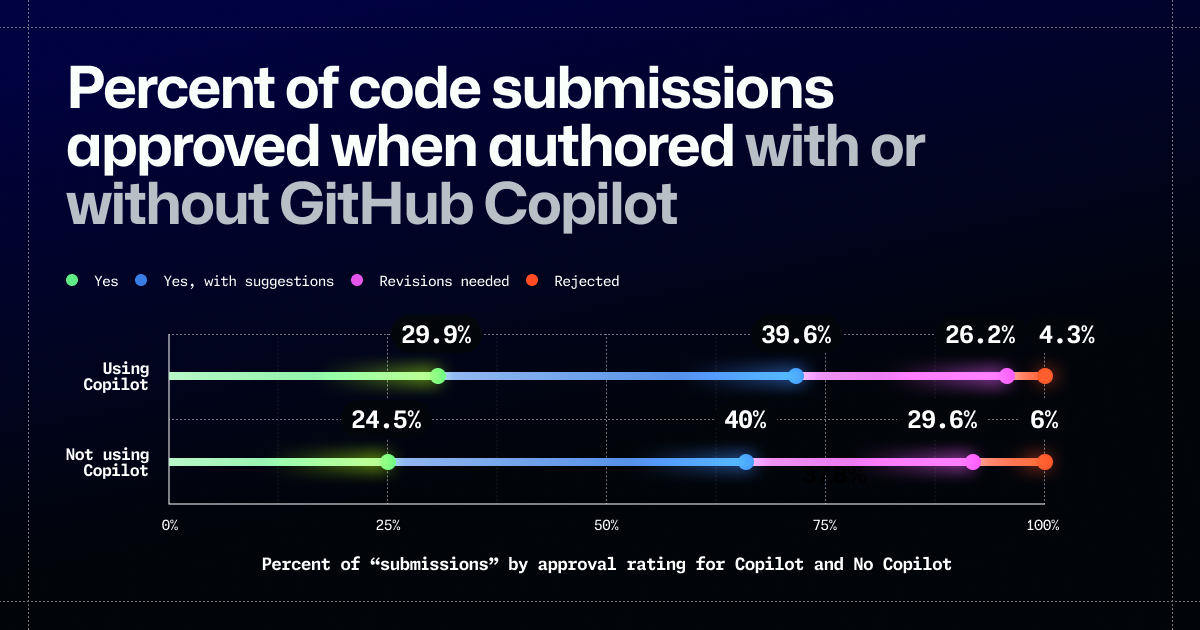
It seems that Copilot-ers get a 5% boon in PRs approved without comments compared to Control-ers. I wonder if they got reviewed after the lunch break…
At any rate, it seems like the rest of the outcomes are relatively close percentage wise. What I would take from this is that even with a test-acing Copilot, you still have a 4.3% chance of submitting code so bad the reviewer closes the PR instead of bothering to comment.
Sample Size #
GitHub prides itself with being “home to 1 Billion developers”, yet could not, for the purposes of researching one of
their most insistently shilled advertised product, bother to study more than 243 developers.
That small sample size alone should be enough to dissuade many, but there’s even more subtlety:
Half were randomly assigned GitHub Copilot access and the other half were instructed not to use any AI tools.
I’ll be nice and give them the benefit of the doubt here, but just hypothetically, they only specified that the control group was instructed not to use any AI tools, and not that the control group is made of developers who didn’t use any AI tools. It would be so funny if the marginal decrease in performance was that they were suddenly deprived by a tool they regularly used.
At the beginning, they state there were 200 developers, split in half using Copilot, and half being a control group. But that’s not the whole story, actually there were 243 developers, so 121 (and a half?) used Copilot, and 121 didn’t. Out of each of those, only 104, respectively 98, gave valid submissions.
What constitutes a valid submission, in the context of trying to evaluate code? Your guess is as good as mine. Does it mean they opted out of the study? Does it mean they submitted code that did not compile at all? Why doesn’t that count, seems pretty important?
And just to be pedantic, 104 vs 98 means 6% more Copilot-ers than Control-ers. Is ThAt SiGnIfIcAnT?
Other Research #
The article prides itself with being “the first controlled study to examine GitHub Copilot’s impact on code quality”. I won’t deny them that, because they really controlled the environment alright.
Let’s perhaps look at other, less controlled studies on GitHub Copilot’s impact on code quality. In 2023, GitClear published a paper1 where data suggested a “downward pressure on code quality”. If you can’t be bothered to register for the PDF, take a look at this Arc article2 summarizing it, or have The Primeagen ASMR it for you3.
This is the table I show to AI coding enthusiasts:
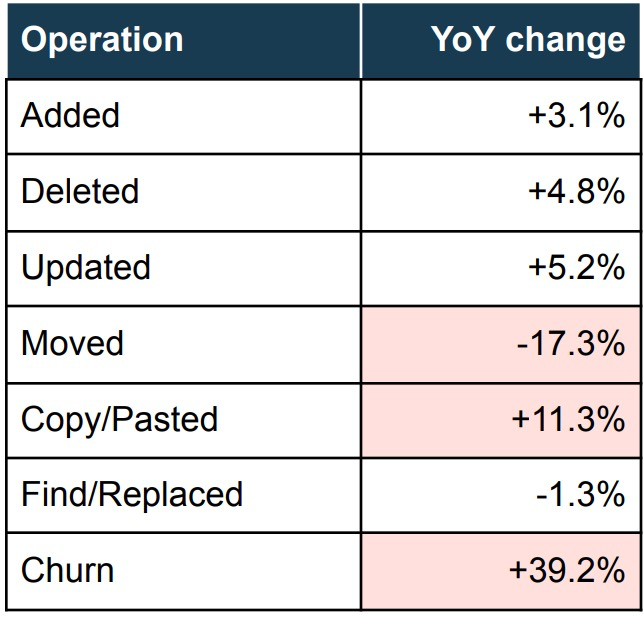
Red Flags for Code Quality in AI-assisted projects, 2020-2023
Even in their own article, GitHub admitted:
While the number of commits and lines of code changed was significantly higher for the GitHub Copilot group, the average commit size was slightly smaller.
What do those higher number of commits and lines of code changed actually translate to in a real-life project scenario?
- A significant decrease in moved code, meaning less refactoring, less cleaning.
- A significant increase in copy-paste, meaning more duplication (which ironically GitHub considered an error), and therefore reduced maintainability.
- A SIGNIFICANT increase in churn rate, meaning code once commited was much more likely to be altered soon thereafter, but surely it’s not because they only caught bugs too late and came back to fix them, it’s because AI is so helpful you just want to use it again! (\s).
To be clear, I’m not trying to cherry-pick this one other study that happens to conform to my worldview in order to convince you otherwise, but I would much rather trust a study made across three years that just observed behavior in actual scenarios spanning tens of millions of lines of code, than a few hundred badly written controllers in a fictitious, PoC-level TDD lab test.
Conclusion #
I was very disappointed with how little effort GitHub made to give credibility to Copilot’s marketing, and even more baffled that after all this contrived experiment, an up to 5% improvement in almost exclusively subjective metrics still seemed to them to be an achievement worthy to brag about.
Because even if I were to grant them an objective, 5% improvement in overall productivity, this does not seem to be even attempting to aimed towards developers, but rather has the perfume of marketing, catered to the C-suites with buying power, trying to convince them that 470$/dev/yr4 is better spent with them, to squeeze out as much bang per buck from their human resources, instead of spending it on the employees as persons.
And as for you, developers, if you can’t write good code without an AI, then you shouldn’t use one in the first place. No matter what space-age technology the AI over-fitters come at you with, nothing can substitute personal experience, and pride in your craft.